DeepSeek公司近期宣布了一項技術創新,正式推出了名為NSA(Native Sparse Attention)的新型稀疏注意力機制。這一機制專為超快速長上下文訓練與推理設計,實現了硬件對齊與原生可訓練性。
NSA的核心組成部分別具一格,涵蓋了動態分層稀疏策略、粗粒度token壓縮以及細粒度token選擇。這些組件的協同作用,使得NSA在提升性能的同時,也優化了現代硬件設計。

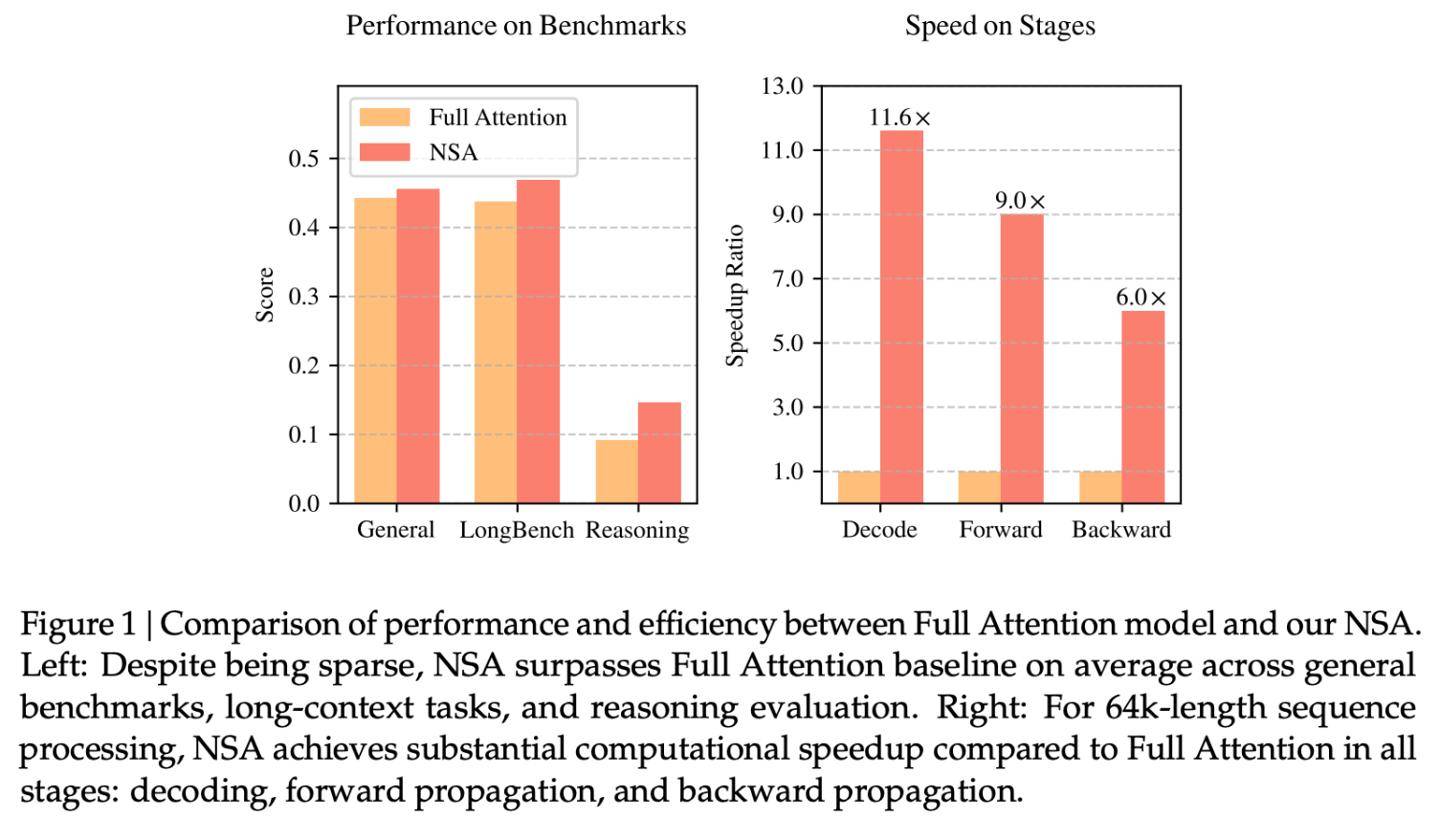
據DeepSeek官方介紹,NSA機制不僅能夠加速推理過程,顯著降低預訓練成本,而且在性能上并未做出妥協。在通用基準測試、長上下文任務以及基于指令的推理場景中,NSA的表現與全注意力模型相比,要么相當,要么更勝一籌。
這一創新技術的推出,對于深度學習領域而言無疑是一個重大突破。通過優化硬件設計與訓練效率,NSA為大規模語言模型的應用開辟了新路徑,使得長上下文處理和快速推理成為可能。
DeepSeek還提供了關于NSA機制的詳細論文鏈接,供相關領域的研究人員和開發者深入了解和探索。