近期,科技界迎來了一項(xiàng)重大突破,meta公司推出了名為LlamaRL的創(chuàng)新框架,這一框架專為強(qiáng)化學(xué)習(xí)在大語言模型中的應(yīng)用而設(shè)計。據(jù)科技媒體marktechpost于6月10日的報道,LlamaRL采用了全異步分布式設(shè)計,極大地提升了訓(xùn)練效率。
強(qiáng)化學(xué)習(xí),作為一種通過反饋調(diào)整輸出以更貼合用戶需求的算法,近年來在先進(jìn)大語言模型系統(tǒng)中扮演著愈發(fā)重要的角色。然而,將強(qiáng)化學(xué)習(xí)應(yīng)用于大語言模型的最大挑戰(zhàn)在于其龐大的資源需求。訓(xùn)練過程中涉及的海量計算和多組件協(xié)調(diào),如策略模型、獎勵評分器等,使得這一過程極為復(fù)雜且耗時。
meta的LlamaRL框架正是為了解決這些問題而生。它基于PyTorch構(gòu)建,采用了全異步分布式系統(tǒng),這一設(shè)計不僅簡化了組件之間的協(xié)調(diào),還支持模塊化定制,使得工程師能夠更靈活地調(diào)整和優(yōu)化模型。通過獨(dú)立執(zhí)行器并行處理生成、訓(xùn)練和獎勵模型,LlamaRL顯著減少了等待時間,從而提升了整體訓(xùn)練效率。
更LlamaRL框架還利用了分布式直接內(nèi)存訪問(DDMA)和NVIDIA NVLink技術(shù),實(shí)現(xiàn)了模型權(quán)重的快速同步。在405B參數(shù)模型上,權(quán)重同步僅需2秒,這一速度的提升無疑為大規(guī)模模型的訓(xùn)練帶來了極大的便利。
在實(shí)際測試中,LlamaRL的表現(xiàn)令人矚目。在8B、70B和405B模型上,它將訓(xùn)練時間分別縮短至8.90秒、20.67秒和59.5秒,速度提升最高達(dá)到了10.7倍。這一成績不僅證明了LlamaRL框架的高效性,也為其在大語言模型訓(xùn)練中的應(yīng)用奠定了堅實(shí)的基礎(chǔ)。
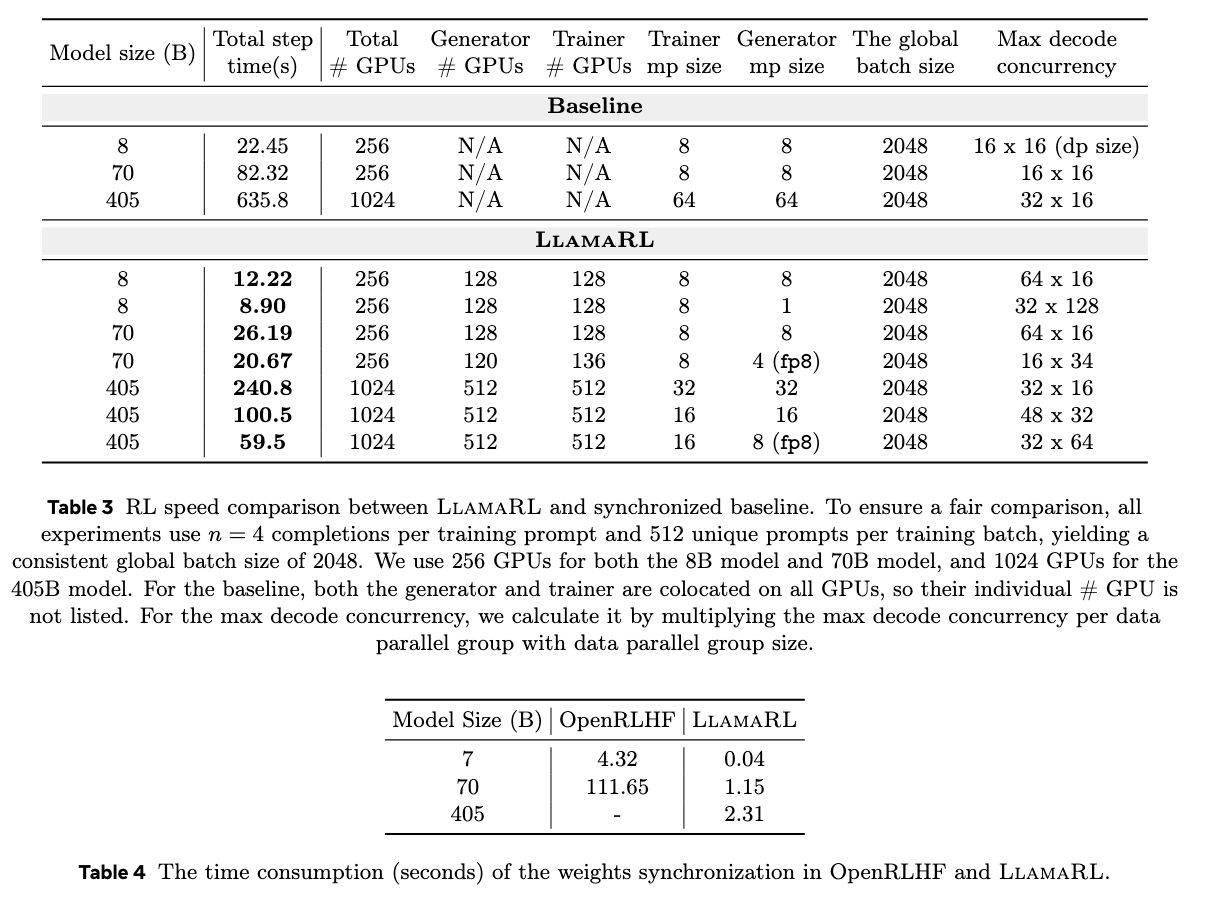
LlamaRL在性能方面也表現(xiàn)出色。在MATH和GSM8K基準(zhǔn)測試中,其性能穩(wěn)定甚至略有提升。這一結(jié)果不僅驗(yàn)證了LlamaRL框架的有效性,也展示了它在解決內(nèi)存限制和GPU效率問題方面的卓越能力。可以說,LlamaRL為訓(xùn)練大語言模型開辟了一條可擴(kuò)展的新路徑。