智元機(jī)器人在科技創(chuàng)新領(lǐng)域邁出了重要一步,正式揭曉了其首個(gè)通用具身基座大模型——智元啟元大模型(簡(jiǎn)稱GO-1)。這一發(fā)布標(biāo)志著具身智能技術(shù)取得了突破性進(jìn)展。
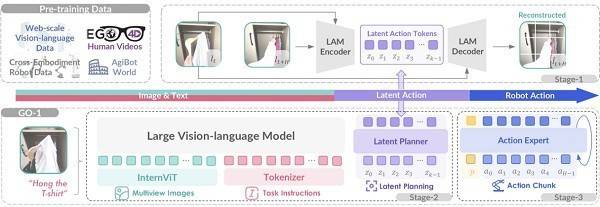
GO-1大模型的核心在于其創(chuàng)新的Vision-Language-Latent-Action(ViLLA)架構(gòu),該架構(gòu)由多模態(tài)大模型(VLM)與混合專家模型(MoE)兩大組件構(gòu)成。VLM通過(guò)海量互聯(lián)網(wǎng)圖文數(shù)據(jù)的訓(xùn)練,獲得了卓越的場(chǎng)景感知和語(yǔ)言理解能力。而MoE則進(jìn)一步細(xì)分為隱式規(guī)劃器(Latent Planner)和動(dòng)作專家(Action Expert),前者通過(guò)大規(guī)模跨本體和人類操作數(shù)據(jù),實(shí)現(xiàn)了對(duì)動(dòng)作的深刻理解;后者則憑借百萬(wàn)真機(jī)數(shù)據(jù)的訓(xùn)練,具備了精細(xì)的動(dòng)作執(zhí)行能力。這三者之間的緊密協(xié)作,不僅使GO-1大模型能夠?qū)W習(xí)人類視頻,還實(shí)現(xiàn)了小樣本快速泛化,極大地降低了具身智能的應(yīng)用門檻。
GO-1大模型的問(wèn)世,意味著具身智能的全面革新。它能夠結(jié)合人類和多種機(jī)器人數(shù)據(jù),使機(jī)器人具備革命性的學(xué)習(xí)能力,可廣泛應(yīng)用于各類環(huán)境和物品中,迅速適應(yīng)新任務(wù),學(xué)習(xí)新技能。同時(shí),GO-1大模型支持部署到不同形態(tài)的機(jī)器人本體,實(shí)現(xiàn)高效落地,并在實(shí)際應(yīng)用中持續(xù)進(jìn)化。
GO-1大模型的四大特點(diǎn)尤為突出:首先,它能夠結(jié)合互聯(lián)網(wǎng)視頻和真實(shí)人類示范進(jìn)行學(xué)習(xí),從而更好地理解人類行為,提升服務(wù)質(zhì)量。其次,GO-1大模型具備強(qiáng)大的小樣本快速泛化能力,能夠在極少數(shù)據(jù)甚至零樣本的情況下,迅速適應(yīng)新場(chǎng)景和新任務(wù),顯著降低了使用門檻和后訓(xùn)練成本。再者,GO-1大模型作為通用機(jī)器人策略模型,能夠在不同機(jī)器人形態(tài)之間遷移,實(shí)現(xiàn)快速適配和群體升智。最后,得益于智元的數(shù)據(jù)回流系統(tǒng),GO-1大模型能夠在實(shí)際執(zhí)行中遇到問(wèn)題時(shí)持續(xù)學(xué)習(xí)進(jìn)化,變得越來(lái)越智能。
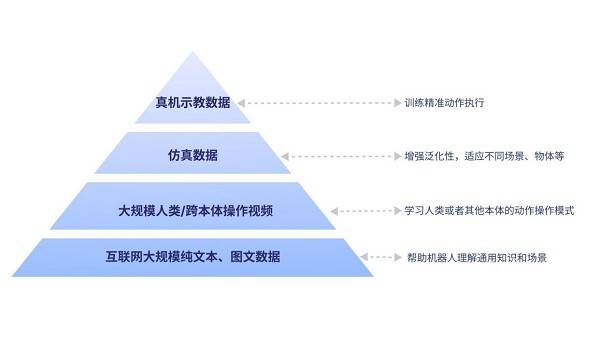
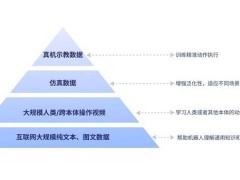
GO-1大模型的構(gòu)建基于具身領(lǐng)域的數(shù)字金字塔模型,該模型吸納了人類世界多種維度和類型的數(shù)據(jù)。數(shù)字金字塔的底層是互聯(lián)網(wǎng)的大規(guī)模純文本與圖文數(shù)據(jù),為機(jī)器人提供通用知識(shí)和場(chǎng)景理解的基礎(chǔ)。往上是大規(guī)模人類操作/跨本體視頻數(shù)據(jù),幫助機(jī)器人學(xué)習(xí)動(dòng)作操作模式。再往上則是用于增強(qiáng)泛化性的仿真數(shù)據(jù),使機(jī)器人能夠適應(yīng)不同場(chǎng)景和物體。而金字塔的頂層,則是高質(zhì)量的真機(jī)示教數(shù)據(jù),用于訓(xùn)練精準(zhǔn)動(dòng)作執(zhí)行。
相較于現(xiàn)有的Vision-Language-Action(VLA)架構(gòu),ViLLA架構(gòu)通過(guò)預(yù)測(cè)隱式動(dòng)作標(biāo)記,有效彌合了圖像-文本輸入與機(jī)器人執(zhí)行動(dòng)作之間的鴻溝。它能夠充分利用高質(zhì)量的AgiBot World數(shù)據(jù)集以及互聯(lián)網(wǎng)大規(guī)模異構(gòu)視頻數(shù)據(jù),顯著增強(qiáng)策略的泛化能力。基于ViLLA架構(gòu),GO-1大模型能夠接收多相機(jī)的視覺(jué)信號(hào)、力覺(jué)信號(hào)、語(yǔ)言指令等多模態(tài)信息,直接輸出機(jī)器人的動(dòng)作執(zhí)行序列。
GO-1大模型為機(jī)器人提供了全面的“基礎(chǔ)教育”和“職業(yè)教育”,使機(jī)器人天生就能適應(yīng)新場(chǎng)景,輕松面對(duì)多樣化的環(huán)境和物體,快速學(xué)習(xí)新的操作。例如,當(dāng)用戶給出“掛衣服”的指令時(shí),GO-1大模型能夠根據(jù)看到的畫(huà)面理解任務(wù)要求,設(shè)想操作步驟,并最終執(zhí)行完成整個(gè)任務(wù)。
在更深層次的技術(shù)層面,GO-1大模型在構(gòu)建和訓(xùn)練階段學(xué)習(xí)了互聯(lián)網(wǎng)的大規(guī)模純文本和圖文數(shù)據(jù),使其能夠理解“掛衣服”在此情此景下的具體含義和要求。同時(shí),通過(guò)學(xué)習(xí)人類操作視頻和其他機(jī)器人的操作視頻,GO-1大模型能夠知道掛衣服通常包括哪些環(huán)節(jié)。通過(guò)仿真不同衣服、衣柜和房間,以及模擬掛衣服的操作,GO-1大模型能夠理解環(huán)節(jié)中對(duì)應(yīng)的物體和環(huán)境,并打通整個(gè)任務(wù)過(guò)程。最后,由于學(xué)習(xí)了真機(jī)的示教數(shù)據(jù),機(jī)器人能夠精準(zhǔn)完成整個(gè)任務(wù)的操作。
GO-1大模型的推出,標(biāo)志著具身智能正朝著通用化、開(kāi)放化、智能化的方向快速邁進(jìn)。機(jī)器人將能夠在不同場(chǎng)景中執(zhí)行多種任務(wù),而無(wú)需針對(duì)每個(gè)新任務(wù)重新訓(xùn)練。同時(shí),機(jī)器人將不再局限于實(shí)驗(yàn)室環(huán)境,而是能夠適應(yīng)多變的真實(shí)世界。機(jī)器人將能夠理解自然語(yǔ)言指令,并根據(jù)語(yǔ)義進(jìn)行組合推理,而不再局限于預(yù)設(shè)程序。