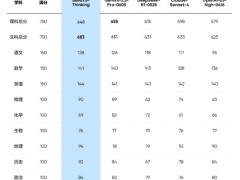
卡帕西指出,軟件開發已經邁入“Software 3.0”時代,這是一個由大語言模型引領的新紀元。在傳統的手寫代碼時代(Software 1.0)和訓練神經網絡權重時代(Software 2.0)之后,大語言模型通過自然語言直接控制計算機,使得“提示詞即程序”成為新的編程范式。這一變化不僅極大地提高了編程效率,還降低了編程門檻,使得更多人能夠參與到軟件開發中來。
卡帕西強調,大語言模型具有三重核心屬性:它們如同電網般的基礎設施服務屬性,需要百億級資本密集投入,類似于芯片晶圓廠;同時,它們也擁有復雜生態構建與分層管理的屬性,類似于操作系統。然而,大語言模型并非完美無缺,它們存在“鋸齒狀智能”的認知缺陷,即在處理復雜任務時表現出色,但在基礎邏輯上卻容易出錯。大語言模型的信息處理能力也受到上下文窗口的限制,一旦信息超出設定范圍,就無法被有效保留。

為了應對大語言模型的自主性控制挑戰,卡帕西提出了仿鋼鐵俠戰甲的動態控制框架。這一框架通過自主性調節器,實現了類似特斯拉Autopilot的L1-L4分級決策權限分配,使得人類可以根據任務的復雜性和風險程度,動態調整AI的自主程度,從而保持對系統的最終控制權。
在演講中,卡帕西還分享了大語言模型在軟件開發中的實際應用案例。例如,在編程場景中,開發者可以直接使用ChatGPT復制粘貼代碼、提交bug報告,而無需直接與操作系統交互。這種部分自主化的應用模式不僅提高了開發效率,還降低了開發難度。卡帕西還提到了Cursor和Perplexity等成功案例,這些應用通過整合多模型調用、提供可審計的GUI和自主滑塊設計,為用戶提供了更加便捷和高效的編程體驗。
卡帕西認為,大語言模型的出現使得軟件變得極具可訪問性,因為自然語言編程使得每個人都能成為程序員。他舉例說,孩子們現在可以通過“Vibe Coding”的方式學習編程,這種基于自然語言交互的編程方式極大地降低了編程門檻。同時,大語言模型也正在成為數字信息的新型主要消費者和操控者,它們需要與我們的軟件基礎設施進行交互。因此,卡帕西呼吁行業內的開發者們積極適應這一變化,為Agent構建更加友好的基礎設施。
卡帕西的演講不僅展示了大語言模型在軟件開發領域的巨大潛力,還為我們揭示了軟件發展的未來趨勢。在這個充滿機遇和挑戰的時代,我們需要不斷學習和創新,以適應軟件行業的快速發展和變革。